Web Scraping
Importing Web Pages Using Web Scraper
The Web Scraper feature allows you to extract and import content from websites directly into your AI assistant’s Knowledge Base. This ensures your AI can reference up-to-date, structured content from online sources.
Step-by-Step Guide to Using the Web Scraper
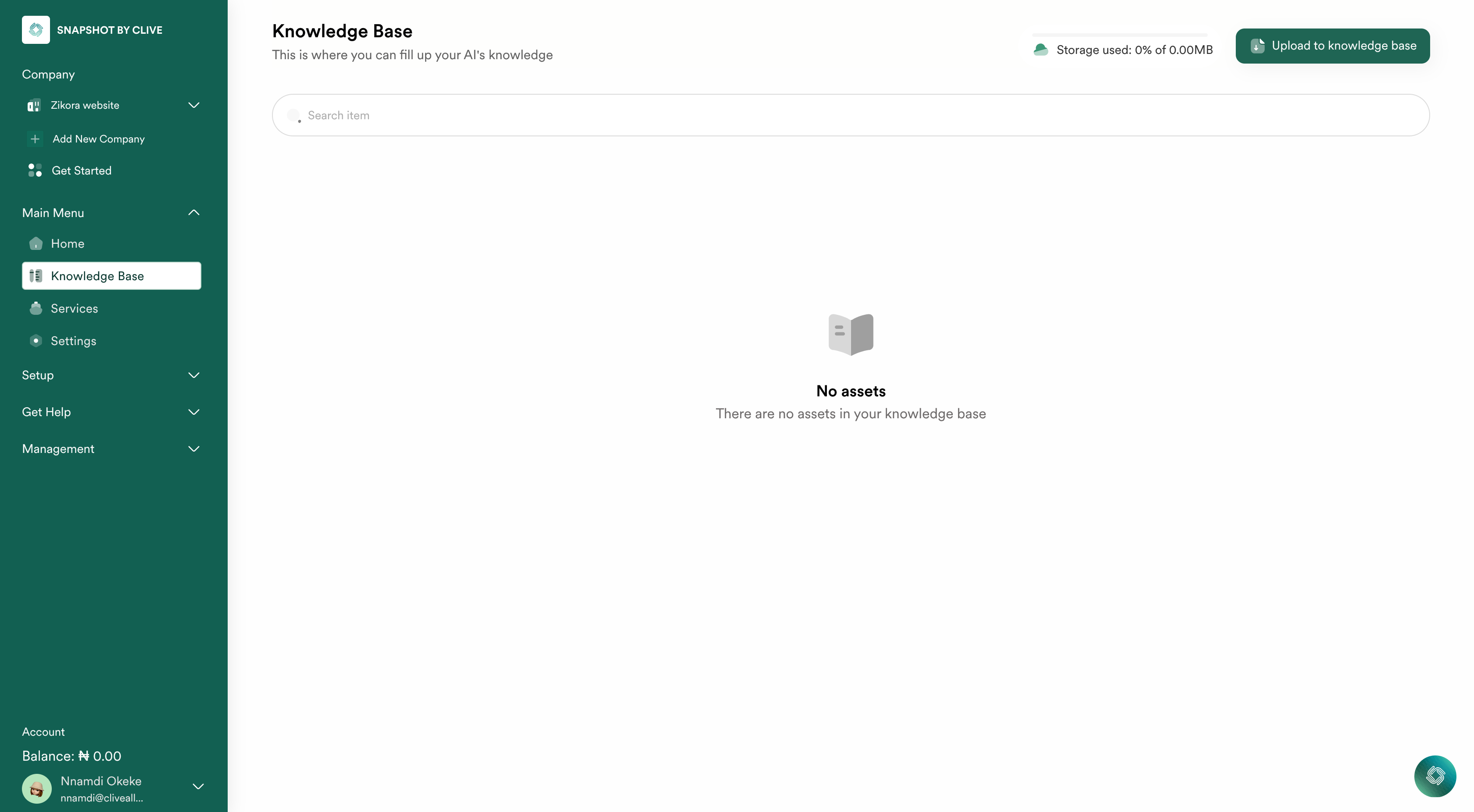
1. Access the Knowledge Base Settings
To begin, navigate to the Knowledge Base section in your AI assistant’s settings:
- Go to Knowledge Base Settings.
- This page lets you manage all the content that your AI assistant can learn from.
2. Click on "Upload to Knowledge Base"
Once you’re on the Knowledge Base settings page:
- Locate the "Upload to Knowledge Base" button at the top right.
- Click it to open the import modal, where you can see multiple import options.
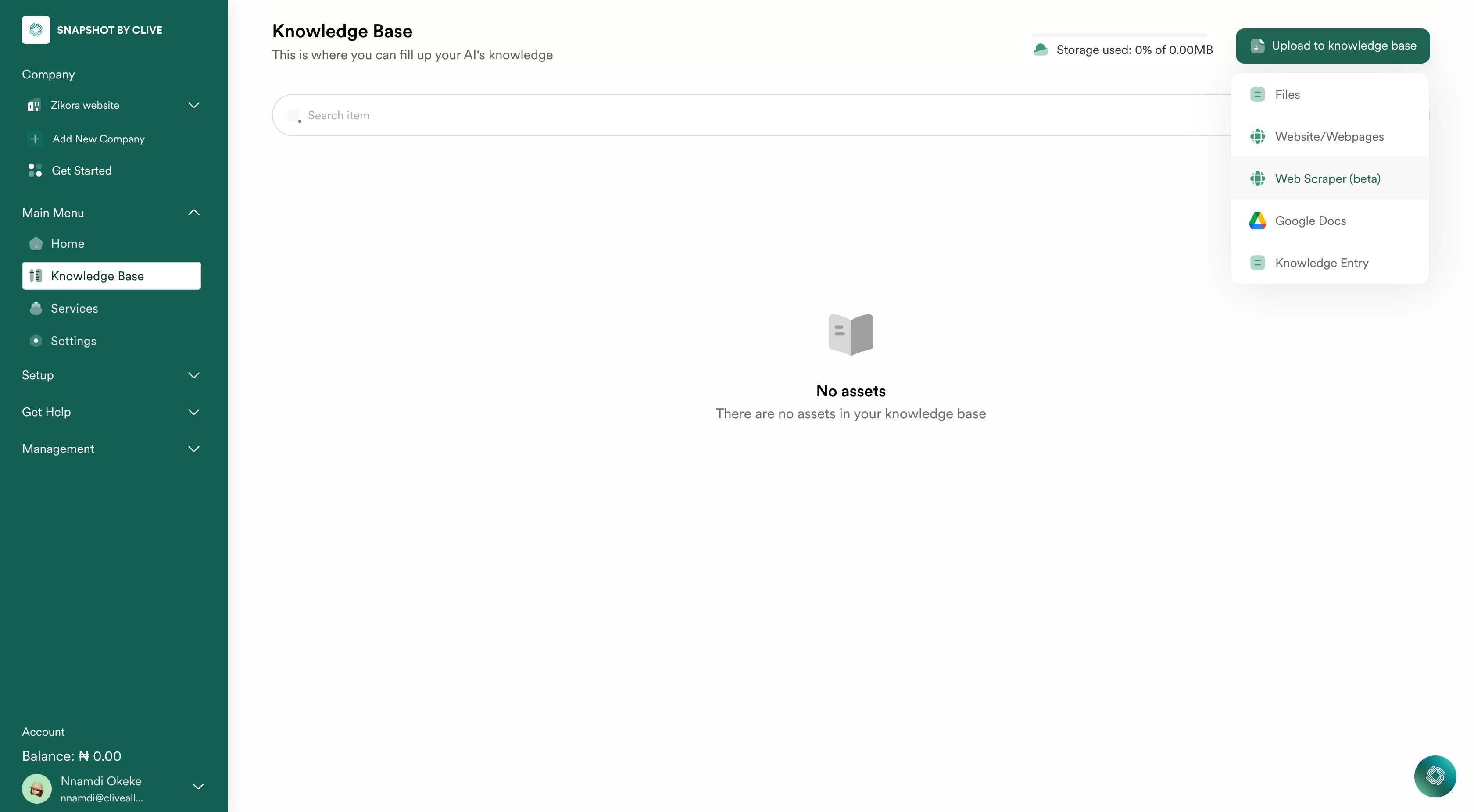
3. Select the "Web Scraper" Option
In the import modal, you’ll see several options for adding content:
- Files – Import PDFs, documents, and other file types.
- Google Docs – Sync content directly from your Google Drive.
- Web Pages – Import website content via direct URL entry or web scraping.
- Knowledge Entry – Manually enter entries to your knowledge base.
To scrape content from a website:
- Click on the "Web Scraper" option.
- A new section will appear, prompting you to enter a URL.
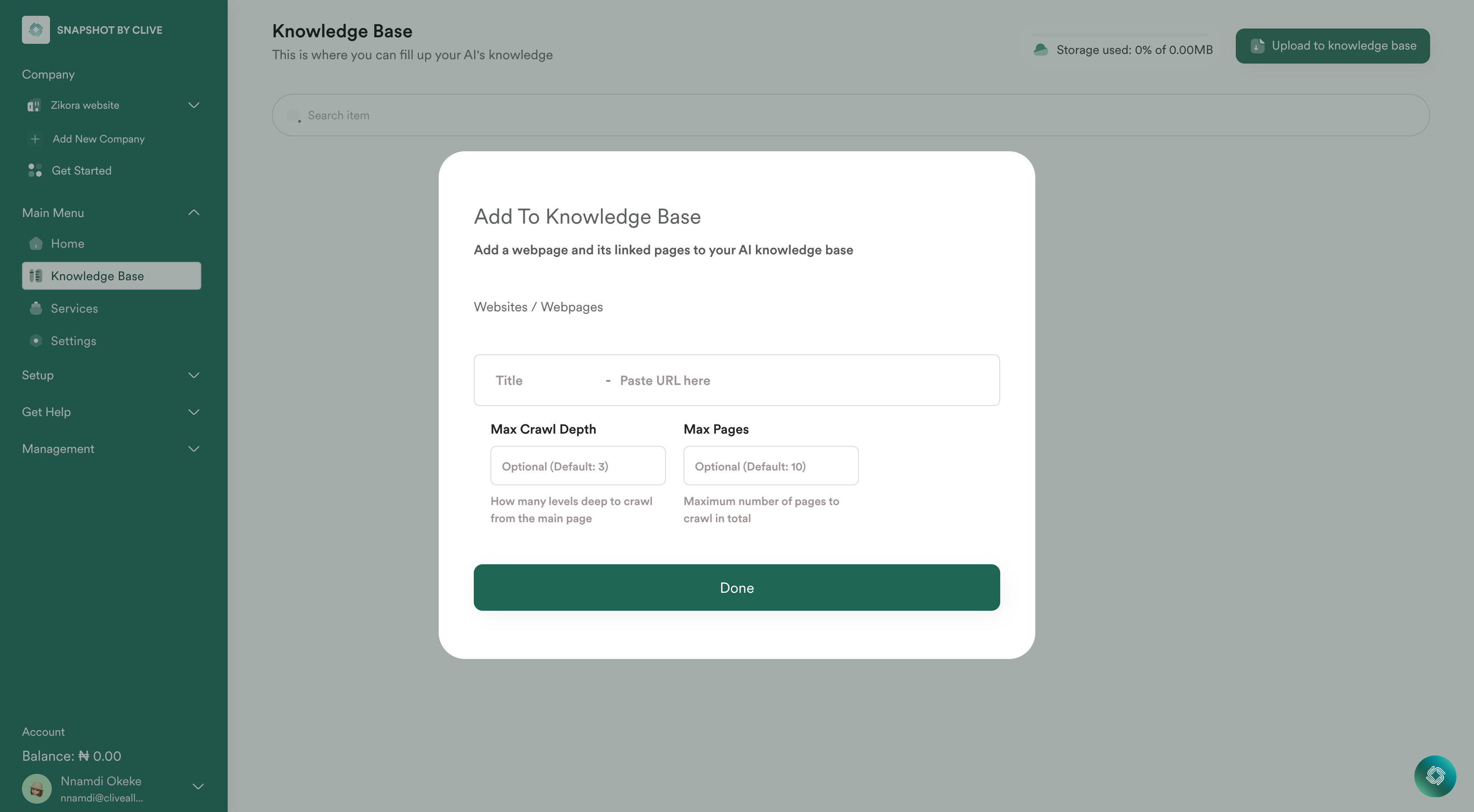
4. Enter the Website URL to Scrape
- In the provided input field, enter the URL of the web page you want to import.
- Select the Max Crawl Depth and Max Pages (optional) then click on done
Important Considerations
- Respect Website Policies – Ensure compliance with the website’s terms of service regarding data extraction.
- Login-Protected Pages – If the content requires authentication, ensure you have the necessary permissions before scraping.
- Dynamic Content Handling – Some websites use JavaScript-based rendering, which may require advanced scraping tools.
By following these steps, you can seamlessly integrate web content into your AI assistant’s Knowledge Base, enhancing its ability to provide accurate and up-to-date responses. 🚀